Modernization of a Legacy Incident Management Platform
When incident management is manual and scattered, teams struggle to track progress. Outages last longer, and customers feel the impact. A UK-based software solutions and consultancy firm engaged Rishabh Software to rebuild and modernize its legacy incident management platform from the ground up. The goal of the engagement was to retain the core incident engine and evolve it into an online incident management system that improves coordination for internal teams and external customers with major feature enhancements.
Capability
Digital Product Engineering
Industry
IT Service Operations
Country
United Kingdom
Key Features
We modernized the mission-critical incident operations platform by rebuilding it with feature enhancements. We combined workflow engineering, cloud architecture, and sprint-based delivery to create a modern, role-driven experience for speed, agility, and accountability. It was delivered as a cloud-based incident management system designed to scale with API integrations that add context and improve coordination.
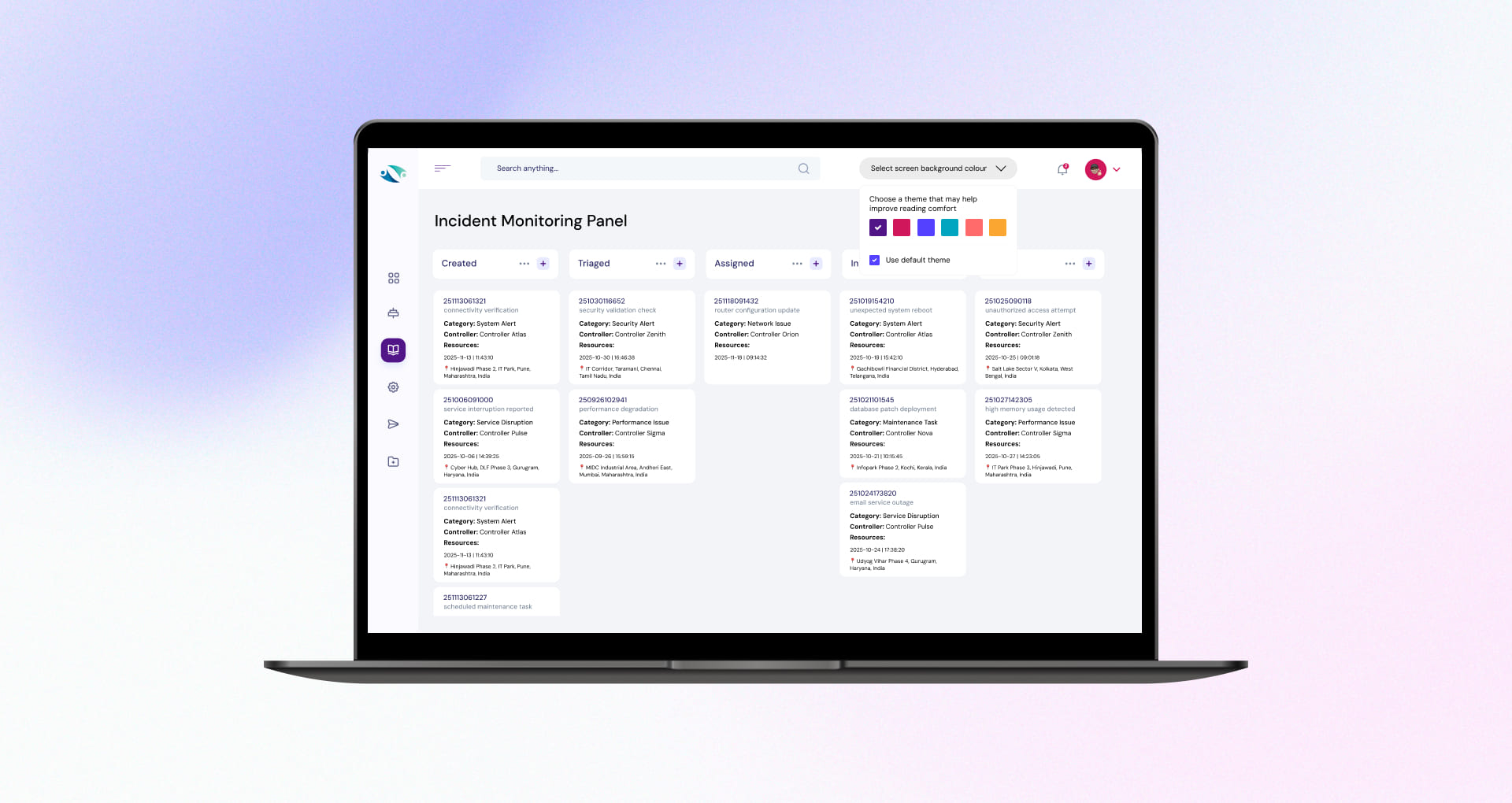
Incident Command Center and Real Time Board
A unified command view enabled teams to track active incidents in real time, quickly prioritize, and take immediate action without switching tools. The board supported operational filtering, fast status updates, and consistent incident reporting across stakeholders.
In-Platform Chat for Faster Coordination
Built-in chat enabled real-time collaboration between coordinators, responders, and stakeholders. This streamlined communication helped teams respond faster and coordinate more effectively during incidents.
Resource Assignment and Capacity Visibility
A centralized resource view helped coordinators assign work with confidence. It reduced duplicate allocations and prevented conflicting ownership. It also improved resource utilization during peak incident periods.
Dyslexia-Friendly View and Color Controls
A dedicated accessibility mode enabled users to switch to dyslexia-friendly visual settings, including color/theme adjustments for better readability and reduced cognitive strain during high-pressure incident response.
End-to-End Incident Lifecycle Governance
We implemented a controlled incident lifecycle with configurable stages, including In Progress, Parked, Resolved, and Archived. This introduced predictable transitions, reduced status ambiguity, and strengthened accountability across teams.
Archival and Institutional Knowledge
Archival incident management capabilities enabled secure storage and rapid retrieval of historical cases, supporting audits, accelerating root-cause analysis, and improving repeat-issue handling by leveraging proven resolutions.
Challenges
Manual handoffs and disconnected workflows created delays that compounded across teams and extended resolution time and downtime impact.
Prioritization was reactive, and trend detection was nearly impossible without live dashboards and consolidated reporting.
Coordinators had limited visibility into availability. Duplicate assignments, gaps in coverage, and conflicting ownership routinely disrupted incident flow.
The platform could not consistently support real-world states such as parked incidents, reopens, escalations, and controlled closures. This resulted in unclear accountability and inconsistent execution.
Without a sandbox, training had to be conducted in live operations, increasing errors and slowing user adoption.
Solutions
The legacy incident platform had become a business risk multiplier. It did not merely slow operations. It reduced control, obscured visibility, and increased the likelihood of SLA failures during high-pressure events. These challenges made modernization urgent because incident operations were central to service delivery and customer experience. Rishabh Software executed a full-scale modernization project to deliver immediate operational gains.
Workflow Re-Engineering and Lifecycle Redesign
We mapped the existing incident journey, identified friction points, and redesigned workflows into a governed lifecycle. We standardized transitions and built controls to ensure incidents moved predictably from creation to closure, reducing ambiguity.
Role-Based Operating Model
We translated operational responsibilities into role-based experiences to ensure that coordinators, managers, and key stakeholders had the required visibility at the right time. This reduced errors, improved accountability, and accelerated execution.
Sandbox and UAT Environment for Adoption at Scale
We introduced dedicated sandbox and UAT environments to enable safe training, onboarding, and hands-on practice without affecting production data. This materially reduced adoption risk and improved rollout readiness.
Operational Visibility and Reporting Enablement
We centralized incident data and enabled reporting readiness to support trend analysis, workload monitoring, and performance oversight. This shifted operations from reactive firefighting to proactive control.
Cloud Hosted Modular Architecture
We implemented a modular architecture hosted on AWS to support scalability, security, and resilience. This created a platform foundation designed for future enhancements and ecosystem expansion.
Agile Delivery with Tight Feedback Loops
We delivered in sprints with weekly governance, demos, and iterative validation. This reduced rework, ensured alignment with real operational needs, and delivered usable increments quickly.
Outcomes
0%
Reduction in incident turnaround time
0%
Reduction in onboarding and training effort
0%
Reduction in time spent generating operational reports
Technologies Used
Project Snapshots
Recent Case Studies
Optimize your cloud infrastructure, implement robust solutions, and stay ahead of trends with our resource hub.