
The wave of enterprise data growth is at its peak, and this change is not going to stop here, but the real shift is in how organizations are responding to it. Instead of relying on traditional data warehouses, C-suite executives are exploring a smarter way to leverage analytics: an agile approach to data-lake development. Unlike static systems, today’s data lake platforms are designed to integrate data lakes across business functions to accelerate product and software system rollout, and support the creation of data-intensive applications, software, & systems without locking into rigidity.
The global data lake market, valued at USD 7.05 billion in 2023, is projected to surge to USD 34.07 billion by 2030, driven by a robust CAGR of nearly 25.3%. The real value lies not just in growth, but in balancing flexibility, governance, and scalability, which determines whether a data lake delivers business value or becomes an untapped asset.
Strategy is key. Organizations that optimize architecture and governance, and align capabilities with business goals, are turning data into a competitive advantage. This blog explores how to navigate data lake strategy from rollout to long-term value creation.
How a Data Lake Strategy Solves Your Data Growth Problem
Nestlé USA, the global food and beverage leader, has moved from fragmented on-premises systems to a unified data lake built on Microsoft Azure. This strategic shift decommissioned 17 legacy systems, onboarded over 2,000 users, and delivered USD 200 million in business value through its Sales Recommendation Engine.
Just like Nestlé, many enterprises face a surge of structured and unstructured data from diverse sources. Fast is fine, but first, you need a clear data lake strategy. Without it, the ability to leverage insights directly and indirectly is lost. Let’s explore the core challenges that a well-implemented data lake strategy addresses—issues that can otherwise impede a business’s ability to leverage its data effectively.
1. Solve Fragmented Insight Challenges with Strategic Consolidation
Today, business leaders grapple with data locked in ERP systems, CRM platforms, and IoT devices, creating blind spots that hinder growth. Data lake strategies become the go-to choice for overcoming this fragmentation. By turning internal tools and siloed datasets into a unified foundation with structure defined only when needed (schema-on-read), organizations unlock clarity across operations. In our experience, this unified approach helps accelerate cross-functional analytics, empowering GTM teams with real-time intelligence that drives strategic decision-making.
2. Architecting Scalable Efficiency Without Overspending
Rising data volumes often force enterprises into expensive, rigid infrastructure options. The smarter route is an incremental, cloud-native architecture that scales storage and compute as needed. By leveraging object storage like AWS S3 or Azure Data Lake Storage, leaders can significantly reduce costs. Crucially, validating your strategy early and bringing subject-matter experts into the planning helps avoid the trap of underutilized infrastructure investments.
3. Enabling Advanced Analytics that Drive Revenue Growth
Legacy systems often fall short when feeding AI or predictive models. A well-designed data lake, however, powers data-driven revenue streams by delivering raw, accessible data ready for ML, analytics, and forecasting. Businesses can derive business value from their existing datasets by turning timestamps, digital logs, and sensor data into predictive indicators. As insights increase and trust forms in data quality, the flywheel effect kicks in, elevating both confidence and opportunity.
4. Accelerating Time-to-Insight with Real-Time Integration
For leaders, “fast is fine, but first you need the right foundation.” A data lake that supports streaming ingestion and unified access to both real-time and historical data creates powerful operational agility. Use cases like dynamic pricing, personalized customer engagement, and instant risk detection become possible. Over time, this capability not only improves execution but also builds trust with stakeholders, recognizing data as a reliable source of intelligence.
5. Monetizing Data Through Market-Ready Value
Some firms make the mistake of treating data purely as an internal asset. A modern data strategy, by contrast, positions data as a product ready for external distribution via data marketplaces or partner channels. That shift begins with strong value propositions, supported by rigorous validation and domain expertise, and grows naturally and regularly as adoption spreads. In this way, organizations create new, incremental revenue while deepening their competitive moat.
Key Components of Data Lake Strategies
Building a true enterprise data lake strategy is less about storing information and more about laying the right plumbing where data lake governance, integration, and discovery take place in parallel. The goal is a business-linked, nuts-and-bolts framework that’s fast, flexible, and ready to serve insights when they matter most.
1. Data Discovery & Collaboration
In large-scale enterprises, data is abundant but elusive. Teams hoard it like treasure yet can’t quite remember where they buried it or if anyone else can use it without stepping on legal landmines. Left unchecked, a promising data lake can drift into “data swamp” territory: deep, murky, and dangerous to navigate.
Technical Foundation:
This is where automated data catalogs earn their keep. Tools like Apache Atlas or AWS Glue Data Catalog do the quiet, essential work: harvesting metadata, mapping schemas, tracking lineage, and attaching business context directly to datasets. The result is a living, breathing index that makes data not just findable, but explainable, searchable by anyone, reusable by everyone.
Business Impact:
- Accelerated Time-to-Insight: A marketing analyst doesn’t need to log an IT ticket just to find customer purchase histories and web engagement data. They can pull it themselves, assemble a campaign, and go live before the weekend.
- Cross-Functional Alignment: Finance, product, and sales work from the same datasets, the same definitions, and the exact numbers, removing the “version of truth” debates that derail quarterly reviews.
2. Enterprise-Wide Integration
Most enterprises don’t have one data problem; they have dozens, each living in a different system. CRM holds one truth, ERP another. IoT sensors keep humming, but no one’s sure where that information goes once it’s collected. The result is a patchwork quilt of insights with more holes than fabric.
Technical Foundation:
Real-time data pipelines, such as Apache Kafka and AWS Kinesis, act as the circulatory system, capturing events as they happen. Change Data Capture (CDC) quietly keeps transactional data in sync across systems. In a hybrid architecture, raw, unstructured data stays in the lake for machine learning, while curated, structured slices flow into the data warehouse for BI dashboards.
Business Impact:
- 360° Customer View: Merge CRM data, help desk tickets, website clickstreams, and social sentiment into a unified profile. The offers become more relevant, and the churn rate goes down.
- Operational Digital Twins: Combine IoT readings with supply chain and financial data to run simulations, predict machine failures before they happen, trim costs, and shorten production cycles.
3. Governance & Security
Data without governance is just a liability waiting to be realized. Done right, governance doesn’t slow down the business; it becomes the reason leaders like you can move faster.
Technical Foundation:
Attribute-Based Access Control (ABAC) ensures that permissions are tied both to who you are and what the dataset contains. Encryption end-to-end, in transit, and at rest shields sensitive data from casual and malicious eyes alike. Automated quality checks, lineage tracking, and audit logs make compliance with GDPR or CCPA not just possible but routine.
Business Impact:
- Risk Reduction: Decision-makers can greenlight bold strategies knowing the data estate is locked down, monitored, and compliant.
- Confidence in Decision-Making: If a KPI spikes or drops unexpectedly, full lineage and quality scoring mean you can trace it back to the source before taking action.
Data Lake Implementation Steps
Building a data lake requires a strategic approach, beginning with clear business objectives and use cases. Each step, from prioritizing data sources to selecting the right architecture, ensures scalability, security, and compliance, ultimately enabling businesses to unlock the full potential of their data while driving measurable outcomes.
Step 1: Business Objectives & Use Cases
What you might initially think your business needs often isn’t what will actually work. Identifying the true data requirements for your data lake takes time, effort, and momentum. This first step is often the toughest and longest climb in your data lake strategy. It can feel overwhelming, anxiety-inducing, and even bring fear of failure. However, by working closely with experienced data engineers like those at Rishabh Software through one-on-one consultations and deep problem analysis, you can transform uncertainty into clarity, setting you firmly on the path to success with expert support at your back.
Key action you can take for sure:
- Give Your Team a Leg Up: Engage stakeholders one or more days per week to ensure continuous collaboration. This ongoing interaction helps in maturing your data lake strategy by aligning diverse perspectives with the strategic direction of your business.
- Focus on a Well-Defined Process: Establish clear steps to identify the value you hope to create from your data lake. Having a structured approach prevents the “make or break” moments that often occur when objectives are vague or poorly communicated.
- Embrace the Learning Curve: Remember, Rome wasn’t built in a day. Start small with pilot use cases, iterate quickly, and refine your approach to reduce risk and build momentum steadily.
Step 2: Prioritize Data Sources Mindfully
Why is this step heavily focusable? As a growing enterprise, you face a vast diversity of data sources, each with unique characteristics. These include: Structured data: Highly organized data from transactional databases, CRM, and ERP systems, Semi-structured data: Flexible formats like JSON, XML, and sensor logs that require specialized parsing, and Unstructured data: Complex sources such as emails, images, videos, and social media feeds, which are difficult to organize and process.
Failing to prioritize can lead to costly mistakes, where upkeep may be even more challenging than initial implementation. Therefore, a systemic, big-picture focus is necessary, one that aligns with the organization-level data lake strategy and drives clear business outcomes.
Key action you can take for sure:
- Take a systematic approach to evaluate data sources based on business impact, accessibility, quality, and compliance. Rishabh Software’s consulting helps you make no-regrets moves aligned with your organization-level data strategy, with less to lose.
- Adopt the mindset of “If we do A, we will get B benefit” prioritize sources that deliver immediate, measurable value. Our proof-of-concept services have dramatically sped up decision-making so far.
- Avoid fixed paths by starting with a manageable set of sources. Our data engineering services and teams build flexible pipelines that grow with your needs, maintaining a systemic, big-picture focus.
- Align prioritization with governance via Rishabh’s consulting to ensure smooth upkeep as your data lake matures.
Practical Criteria and Frameworks for Prioritization
A practical framework to rank data sources could include:
| Criteria | Description | Scoring Example (1-5) |
| Business Value | Contribution to key KPIs and strategic goals | 5 = High impact; 1 = Low impact |
| Data Quality | Accuracy, completeness, and timeliness | 5 = Excellent; 1 = Poor |
| Accessibility | Ease of extraction and integration | 5 = Readily accessible; 1 = Difficult |
| Security & Compliance | Risk and regulatory implications | 5 = Low risk; 1 = High risk |
Step 3: Choose an architecture that is scalable, secure, and compliant
Think of your data lake like a developing city. It may start small, but it expands over time. Thus, it needs stronger infrastructure, faster roads for data movement, security controls to protect sensitive information, and clear governance rules to maintain order. Choosing the right data lake architecture is what keeps hurdles at bay, provides security at the core, and has zero compliance issues. These factors collectively pave the way for your business to pursue long-term growth and sustainability.
Here is the architecture pattern you can choose according to your business requirements.
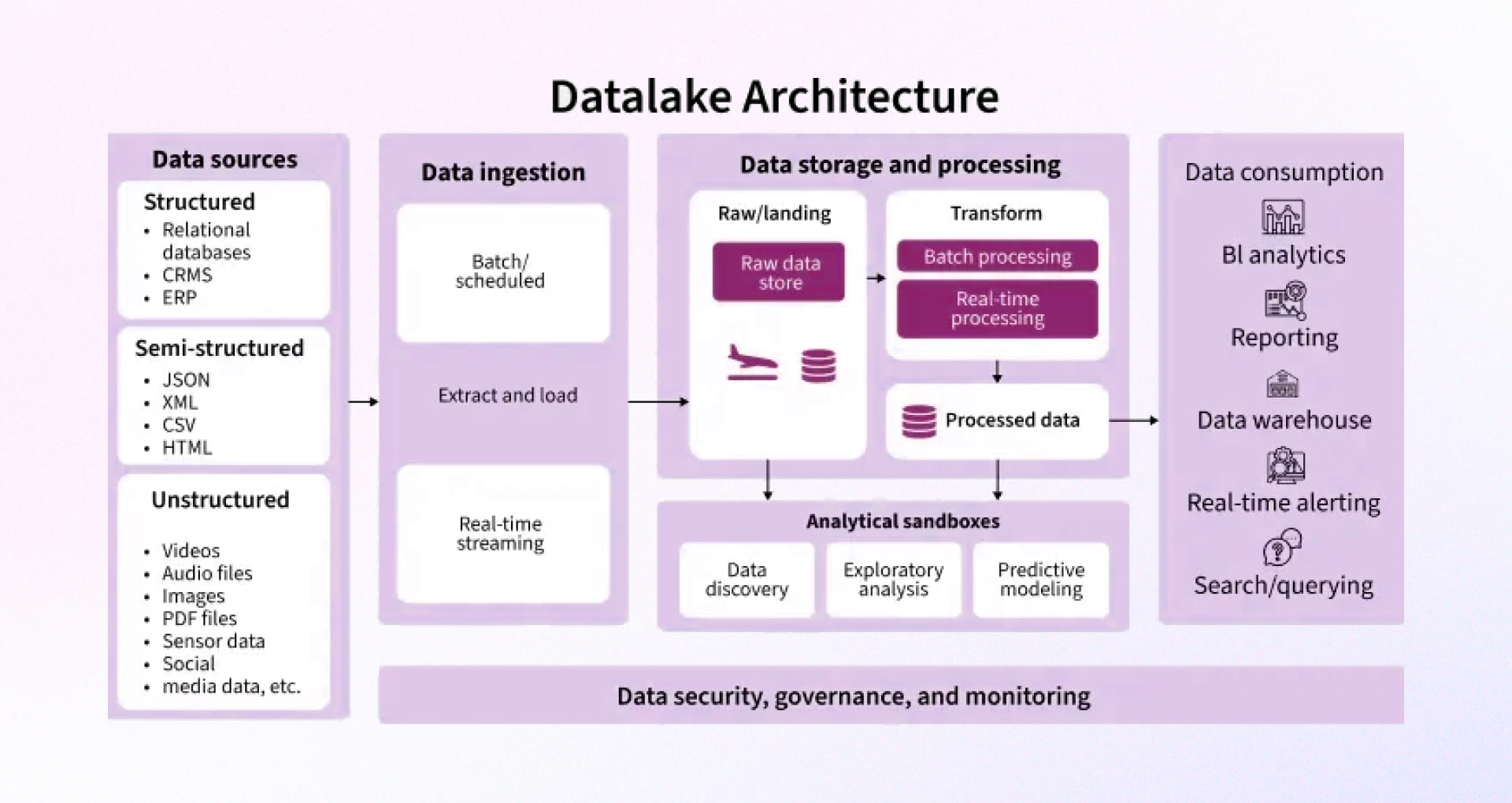
Architecture patterns (what to pick and when)
1. Cloud object storage data lake (simple, scalable)
Use when you want a fast start, especially with unpredictable data volume.
Why it matters: Near-unlimited storage, low operational load; add services like AWS Lake Formation or Glue for access control and cataloging.
In the wild: Netflix hosts massive data lakes on AWS, optimizing for scale without sacrificing performance.
2. Lakehouse with a transactional layer (scalable + reliable)
Use when you need ACID guarantees, versioning, and support for batch + streaming.
Why it matters: Combines scalability with transactional integrity.
In the wild: Netflix migrated to Apache Iceberg for exabyte-scale reliability and performance Wikipedia, Uber built and open-sourced Apache Hudi within Michelangelo, enabling incremental ETL and versioned workflows Uber
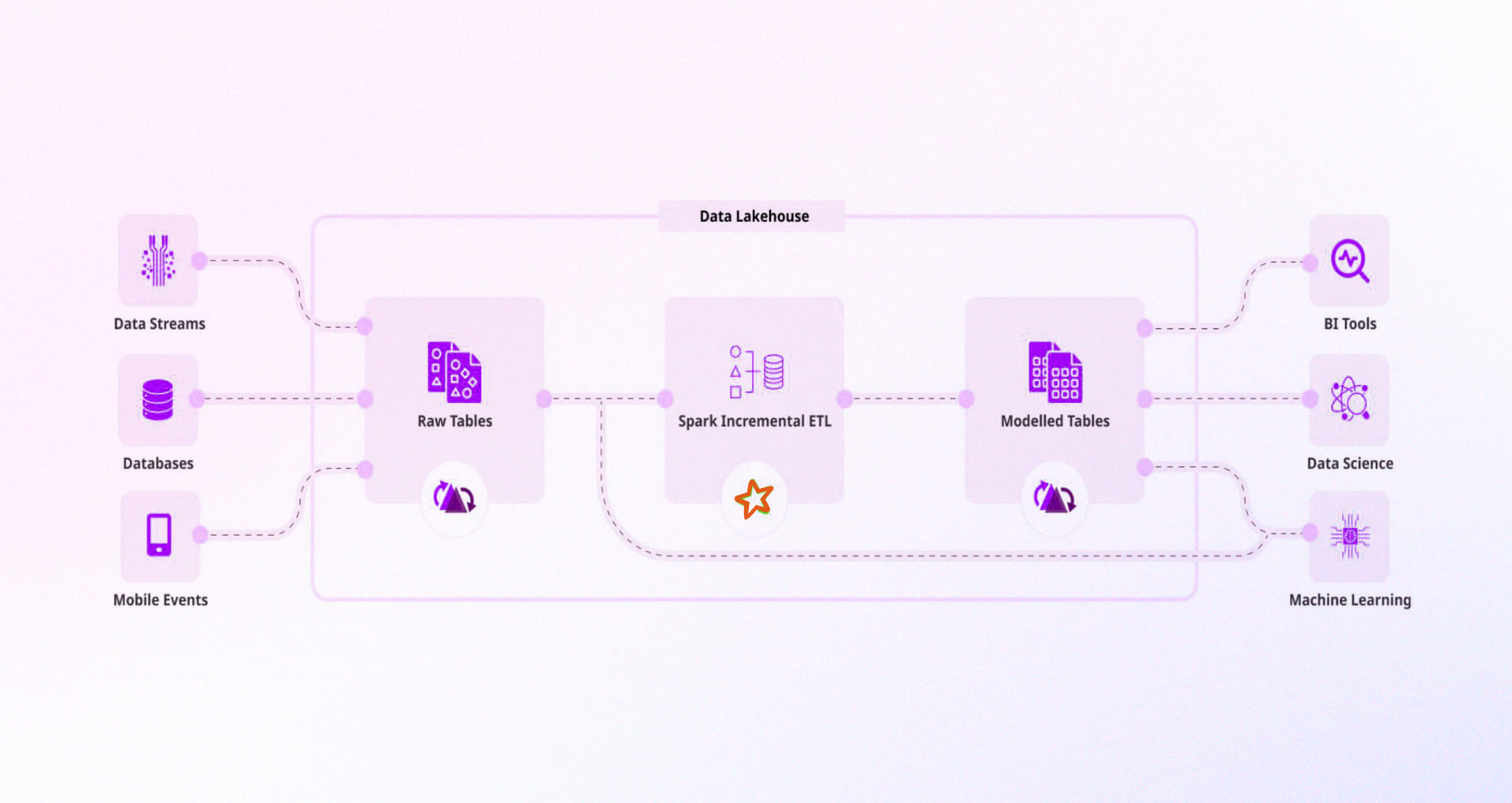
3. Managed lake house platforms (fast to adopt, enterprise controls)
Use when you want unified governance, compute, and rapid adoption.
Why it matters: Eliminates operational friction and centralizes data governance.
In the wild: Enterprises like Comcast and HSBC run data engineering and ML on Databrick
4. Hybrid or on-prem + cloud (compliance focused)
Use when you face regulatory, latency, or location-based demands.
Why it matters: Controls sensitive data locally while letting cloud analytics power broader workloads, employ strong encryption, and unified governance.
Step 4: Build Flexible Data Ingestion & Processing
Design ingestion pipelines that are resilient, adaptive, and format-agnostic, capable of handling structured, semi-structured, and unstructured data at any scale. Blend real-time streaming for time-sensitive insights with batch processing for high-volume workloads. Organize data into raw, processed, and consumption-ready zones to maintain clarity and traceability across the lifecycle. Leverage schema-on-read, columnar storage formats like Parquet or ORC, and auto-scaling orchestration to sustain performance under changing demand.
Key considerations:
- Integrate sources across ERP, IoT, APIs, and machine logs.
- Utilize robust ingestion frameworks (Apache NiFi, Kafka, AWS Glue).
- Implement monitoring and alerting with Grafana or Prometheus.
- Ensure transformations adapt to evolving data formats without downtime.
Step 5: Establish Governance, Metadata Management & Analytics Enablement
Implement governance as a built-in architectural pillar, not an afterthought. Use a centralized metadata catalog to document data lineage, ownership, and usage context, enabling faster discovery and compliance readiness. Apply role-based access, encryption at rest and in transit, and automated audit trails to meet industry regulations without slowing operations. Modern platforms such as Apache Atlas, Collibra, or AWS Lake Formation can automate classification, tagging, and approval workflows, ensuring datasets remain both trusted and analysis-ready.
Key considerations:
- Maintain a unified business glossary for shared understanding.
- Automate classification and data quality checks at ingestion.
- Align access policies with GDPR, HIPAA, or regional compliance needs.
- Track data consumption patterns to prioritize optimization efforts.
Advanced Challenges in Data Lake Strategy & Next-Gen Solutions
Building a robust data lake strategy today means navigating complexity at scale. Success requires rethinking old approaches rather than limiting efforts. This section uncovers the core challenges enterprises face, bridges the gap between raw data and value-adding insights in mission-critical areas, and highlights modern enablers proven to succeed beyond simple storage.
| Challenge | Insight | Strategic Solution |
| The “Schema-on-Read” Paradox | In theory, schema-on-read is a liberating principle: store now, define later. In practice, it can be the “wild west” of data where what accelerates ingestion today becomes the very drag anchor tomorrow. We’ve seen global manufacturers lose weeks reconciling “simple” sales reports across geographies because every analyst shaped the data differently. The result? Insights arrive late, trust erodes, and operational decisions suffer. | Implement a Medallion Architecture & Evolve to a Data Lakehouse: Structure your lake into Bronze (raw), Silver (refined), and Gold (curated) layers. This hybrid marries the openness of a data lake with the discipline of a warehouse. Like a city zoning plan, it ensures every dataset has a place, a purpose, and a path to becoming business-ready accelerating time to insight without sacrificing reliability. |
| Lack of ACID Transactions and Reliability | In mission-critical analytics, “almost correct” is simply wrong. Traditional lakes, without ACID guarantees, risk producing partial or corrupted data when pipelines falter akin to publishing a newspaper missing half its pages. One financial services firm learned this the hard way when an incomplete overnight load skewed risk models, triggering a costly trading halt. | Adopt Transactional Storage Layers: Technologies such as Delta Lake, Apache Iceberg, and Apache Hudi overlay cloud object storage with ACID compliance, version control, and “time travel” capabilities. This transforms the lake into a system of record auditable, resilient, and equally adept at handling batch or streaming data. |
| Monolithic Data Platform Syndrome | The instinct to centralize can be the very thing that slows you down “the bigger the ship, the harder it is to turn.” All-in-one platforms often become over-engineered fortresses: costly, rigid, and slow to evolve. A large retail group found that adding a new marketing analytics feature required a nine-month change request cycle, simply because the monolith left no room for modular innovation. | Shift to a Data Mesh Paradigm: Delegate data ownership to domain teams Sales, Finance, Marketing under a federated governance model. Each domain treats its data as a product, ensuring proximity to the source, faster delivery, and deeper relevance. Like moving from a single command center to a network of well-coordinated outposts, agility increases without losing oversight. |
| Poor Data Discovery and Contextual Understanding | A dataset without context is like a map without a legend it may look complete, but no one knows how to read it. Even with catalogs, many organizations find users lost in a maze of assets, unsure of lineage, quality, or meaning. This fuels duplication, inconsistency, and distrust. In one insurer, different teams paid consultants to produce nearly identical fraud detection datasets simply because neither knew the other’s work existed. | Build a Semantic Layer & Enrich Metadata Management: Go beyond static catalogs. Embed business concepts into a semantic layer, automate lineage tracking, and surface quality metrics. This creates “narrated” data assets clear, contextual, and ready to be trusted. The effect is like turning a dusty archive into a modern research library, complete with knowledgeable librarians. |
| Spiraling Costs and Inefficient Resource Use | Without a clear separation of compute and storage, costs can balloon invisibly, much like leaving all the lights on in an unused office tower. Multi-cloud and hybrid strategies exacerbate this, as redundant workloads and vendor lock-in erode budgets. A logistics firm cut 30% of its annual data spend simply by redesigning queries to avoid reprocessing the same terabytes nightly. | Decouple Compute & Storage with Cost-Optimized Engines: Architect to scale each independently, selecting query engines like Presto, Trino, or Databricks Spark for flexibility. Implement intelligent lifecycle management to tier data according to access patterns hot, warm, and cold so you pay only for the performance you need. |
| Navigating Privacy, Security, and Compliance | In the age of GDPR and CCPA, “trust is earned in drops and lost in buckets.” Data lakes, by their scale, concentrate risk. Managing fine-grained access across diverse users without grinding innovation to a halt is no small feat. One healthcare provider avoided a multi-million-dollar penalty by detecting an unauthorized access pattern thanks to unified, automated governance. | Automate Governance via Unified Catalogs: Deploy platforms like Unity Catalog or Microsoft Purview to centralize policy enforcement, lineage, and auditing. These frameworks enable surgical precision in access control ensuring compliance without creating bottlenecks turning governance from a roadblock into a guardrail. |
Popular Data Lake Platforms to Count On
-
Amazon S3 (along with AWS Lake Formation)
Vast, secure storage combined with AWS Lake Formation and Amazon S3 allows for a simple way to build and manage a data lake with little infrastructure burden.
-
Microsoft Azure Data Lake Storage
Data Lake Storage from Microsoft Azure is a great tool for integrating into its ecosystem to add additional storage and state-of-the-art analytics and AI tools.
-
Google Cloud Storage (coupled with Dataproc and BigLake)
Google Cloud Storage utilizes flexible formats for data lakes, combined with Dataproc and BigLake, to give a seamless feel to the analytics on data lakes and data warehouses.
-
Snowflake
Snowflake gives access to a new range of data types similar to a data lake, while providing governance and sharing of that data the experience of a data warehouse.
Read our blog on Azure Synapse Vs Snowflake
-
Databricks Lakehouse Platform
Databricks allows users to collaborate around data engineering and data analytics in a single platform based on Apache Spark allowing Data Lakes and Warehousing to come together.
-
Cloudera Data Platform (CDP)
Cloudera offers enterprise-grade hybrid data lakes that are governed and secured across clouds and on-prem, with strong integration supporting the right data access for enterprise big data tools.
Let Rishabh Software Guide Your Data Lake Journey
Navigating a data lake journey without the right literacy in architecture, governance, and security is like sailing without a compass; you may find yourself moving, but can’t be sure if it is in the right direction. Many organizations face a glass-half-full problem, seeing potential but struggling to unlock it due to confusion about strategy or choking value through poorly aligned execution. Add to that evolving compliance rules and shifting business models, and the complexity multiplies.
Here’s where the right partner changes the game. At Rishabh Software, we bridge the gap between technical depth and business needs, ensuring your data lake is built to scale, secure, and serve. Our expertise in data engineering, cloud services, AI, IoT, and analytics means we don’t just build systems, we create ecosystems. As the saying goes, “A stitch in time saves nine,” and our proactive approach ensures your data lake delivers long-term, compounding value.
Frequently Asked Questions
Q: What role does data governance play in a data lake strategy?
A: Data governance safeguards the accuracy, security, and compliance of your data lake. It defines how data is classified, accessed, and documented, ensuring it remains trustworthy and usable for analytics.
Q: What are the best practices to implement a data lake strategy?
A: Keep in mind to align with business goals, select a scalable, secure architecture, establish clear ingestion and processing workflows, embed metadata and governance early, and monitor performance to adapt as data needs grow.







