
Enterprises generate massive volumes of data from various sources, yet more often, their data remains trapped in silos or underutilized. Extracting optimal value also becomes challenging due to difficulties in capturing, storing, and analyzing data effectively. This is where scalable data pipeline development can help you transform raw data into actionable insights that drive profitable decisions.
With the growing infusion of AI and machine learning into analytics workflows, the importance of real-time data pipelines has surged. These big data pipelines are no longer just backend infrastructure; they’re the basis of intelligent decision-making. They power use cases from predictive maintenance to personalized customer experiences.
However, designing a reliable, structured, and scalable pipeline is complex and calls for efficient integration of collection, transformation, and delivery processes. This guide covers all the steps on how to build a data pipeline along with real-world applications, ROI considerations, ML integration and common challenges with solutions.
Why Do You Need a Data Pipeline?
Data pipelines are essential for modern data management and real-time analytics. Data-driven enterprises can seamlessly collect, store, and analyze massive datasets to generate actionable insights and long-term strategic value by implementing a scalable big data pipeline. Here are some functions and benefits that help in understanding its importance and why your business should build a data pipeline.
- Automates Data Flow: Streamlines data collection by extracting, transforming, and loading data from various sources, reducing manual effort and allowing focus on priority tasks.
- Enables Data Integration: Combines data into a unified format for easier analysis, providing a holistic view of operations across diverse platforms.
- Scalability & Efficiency: Handles increasing data volumes efficiently, adapting to growth in volume, variety, and velocity as organizations expand.
- Ensures Data Quality: Maintains data quality through cleansing and transformation processes, ensuring accuracy and reliability for informed decision-making.
- Supports Real-Time Processing: Real-time data pipelines enable real-time data processing which helps businesses to respond instantly to changing conditions. They can make smarter decisions through continuous streaming analytics and act on insights immediately, which is crucial for fraud detection and operational monitoring applications
How to Build a Data Pipeline: A Step-by-Step Roadmap
Here’s a comprehensive roadmap that covers the key stages of developing data pipelines:
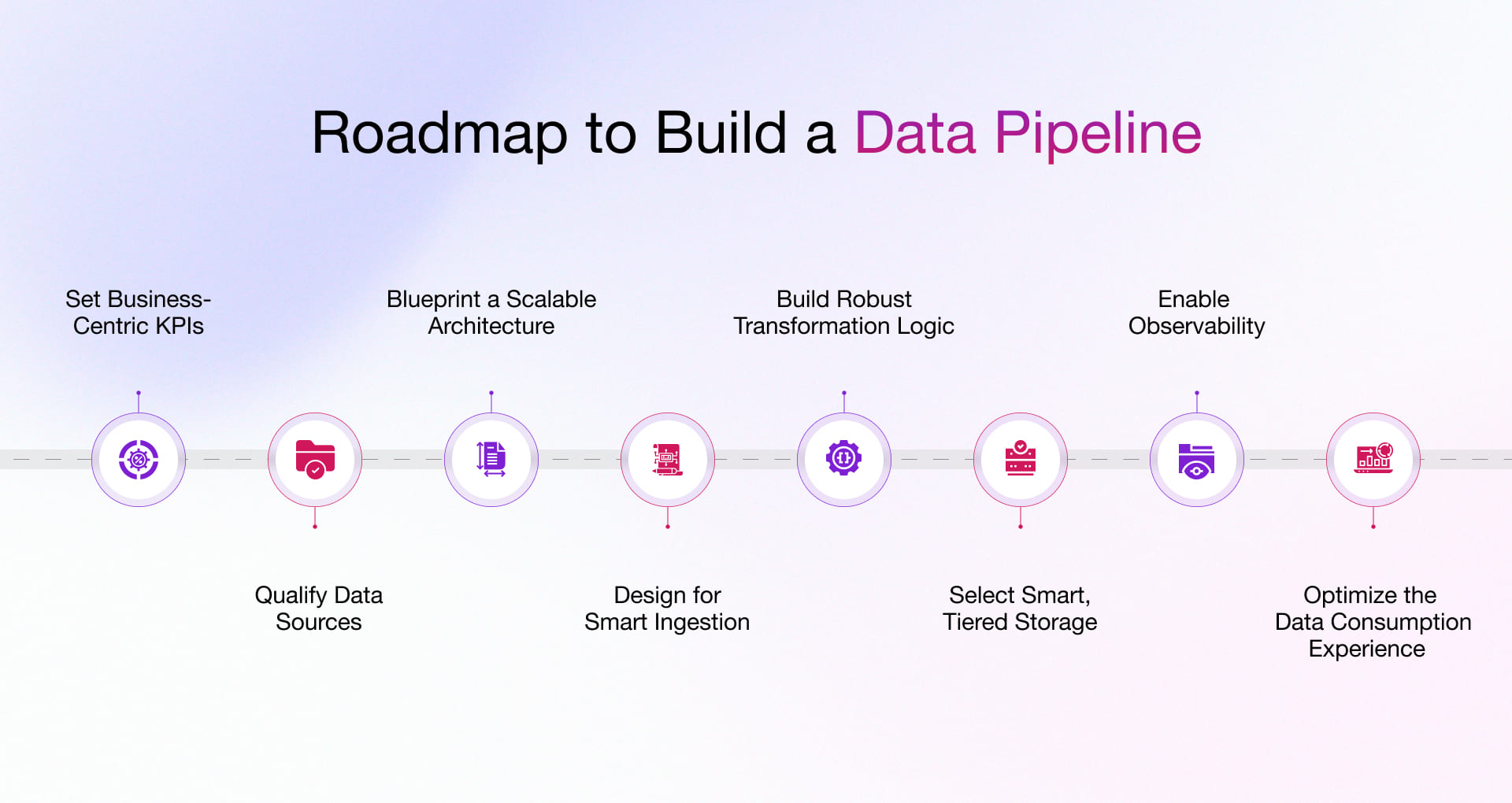
Step 1: Set Business-Centric Objectives and KPIs
Before diving into the tech stack, anchor your pipeline to clear business outcomes. Use these questions as guardrails:
- What specific decisions or processes will this pipeline support?
- What KPIs will measure pipeline success (e.g., latency, accuracy, freshness)?
- Who are the primary stakeholders (analysts, engineers, product teams)?
Pro Tip: Conduct a stakeholder alignment workshop to gather these inputs early.
Step 2: Map and Qualify Data Sources
Don’t just list data sources; qualify them based on:
- Data relevance and richness toward your objectives.
- Latency, update frequency, and integration complexity.
- Legal, compliance, and SLA constraints.
- Prioritize low-risk, high-value sources in your MVP phase.
Pro Tip: Use a “Source Scorecard” matrix to rank each data source for effort vs. impact.
Step 3: Blueprint the Architecture with Scalability in Mind
- Design a pipeline that’s not just functional but future-proof:
- Use modular, decoupled components (ingestion, processing, storage, consumption).
- Adopt cloud-native and containerized architectures (e.g., Kubernetes, Fargate).
- Consider multi-region support and disaster recovery needs early.
Pro Tip: Use architecture-as-code (e.g., Terraform) to version and audit your infrastructure.
Step 4: Design for Smart Ingestion
- Go beyond batch/streaming dichotomy:
- Use event-driven ingestion (e.g., webhooks, Kafka, Kinesis) for high-frequency changes.
- Batch when data consistency is more critical than freshness.
- Orchestrate via Airflow or Dagster to dynamically switch modes based on conditions.
Pro Tip: Include a retry-logic and dead-letter queue mechanism.
Step 5: Build Robust Transformation Logic
Implement transformation layers that:
- Use versioned, modular code (e.g., dbt, PySpark scripts).
- Handle schema evolution gracefully with data contracts.
- Add metadata enrichment to enable lineage tracking and governance.
Pro Tip: Avoid deeply nested transformations in one step; separate into logical stages.
Step 6: Select Smart, Tiered Storage
- Enhanced: Introduces storage tiering strategy.
- Pick not just a storage solution, but plan tiered layers:
- Raw zone (immutable backups)
- Staging zone (for transformations)
- Curated zone (analytics-ready)
- Use lifecycle rules to optimize cost (cold vs hot storage).
Pro Tip: Consider tools like LakeFS for Git-like control over data lakes.
Step 7: Enable Observability, Not Just Monitoring
- Use tools like Monte Carlo, Databand, or OpenLineage.
- Track data freshness, row-level anomalies, lineage, and drift.
- Implement alerting systems based on SLAs/SLIs, not just system metrics.
Pro Tip: Build a dashboard combining pipeline health + business KPIs.
Step 8: Optimize the Data Consumption Experience
- Ensure data is not only delivered but actionable:
- Package as APIs, dashboards, or semantic layers (e.g., LookML, Cube.js).
- Integrate with ML platforms if predictive use is expected.
- Deliver metadata catalogs or self-serve interfaces for business teams.
Pro Tip: Include usage analytics to see which data products drive real business impact.
An efficient data processing pipeline automates data cleansing, transformation, and enrichment to deliver reliable, high-quality inputs for advanced analytics and machine learning models. To learn more about effective data pipeline design and management, check out our blog post on data pipeline best practices.
Common Challenges in Data Pipeline Development and Their Solutions
Several common challenges can arise while designing data pipelines. Below is an exploration of these challenges and their respective solutions.
Data Quality Issues
Poor data governance can easily impact the decision-making process and business outcomes. Data that is incomplete, inconsistent, or contains errors can create complications in the transformation and integration processes.
Solution
Implement robust data validation and cleansing processes within the pipeline. This includes using automated tools to check for anomalies, duplicates, and formatting issues before processing data. Auditing daily can help maintain data integrity with time.
Scalability
As data volumes grow, pipelines can become bottlenecks, leading to performance issues. Traditional architectures may struggle to scale efficiently with increasing data loads.
Solution
While designing data pipelines, it is good to prioritize scalability. Utilizing cloud-based solutions allows for dynamic resource allocation, enabling the pipeline to handle varying data volumes. Technologies like Apache Kafka for streaming data and distributed processing frameworks like Apache Spark can enhance scalability.
Multiple Data Sources Integration
Data collection from multiple sources is common but may come in different formats, structures, or relationships. Integrating all these data sources can be a hassle for businesses and often involves complex challenges.
Solution
Use data integration tools that support various formats and protocols. Implementing an ETL process is also another way to make the integration process seamless. At the initial level, the adoption of microservices architecture can unlock the way to smooth integration and management of multiple data sources.
Real-Time Processing Requirements
Various applications require real-time data processing in order to provide immediate insights. This can be challenging to implement effectively.
Solution
When building data pipelines, businesses can opt for a streaming approach that can process data in real-time by utilizing technologies like Apache Flink or Apache Beam. It allows continuous data processing and immediate analytics, ensuring timely insights for decision-making.
Complexity of Data Transformation
Data often requires significant transformation before it can be analyzed. This can involve complex operations that are difficult to manage and maintain.
Solution
Simplify transformation processes by using modular and reusable components. Implementing a well-defined transformation framework can help manage complexity. Explore visual data transformation tools that can make it easier for data engineers to design and modify transformations without extensive coding.
Monitoring and Maintenance
The absence of proactive post-deployment monitoring could result in data quality or performance degradation. Early detection of issues and continuous monitoring are critical to maintaining data integrity and meeting defined SLA for data delivery and processing times. However, it can be challenging without proper tools.
Solution
Implement comprehensive observability solutions that provide real-time insights into pipeline performance. Orchestration tools manage the workflow, schedule tasks, and handle dependencies between pipeline components. Automated alerting systems can notify teams of failures or performance degradation. Regular maintenance schedules and documentation can also help ensure the pipeline remains efficient and reliable. Data pipeline automation can significantly enhance this component by reducing manual intervention and improving overall efficiency.
Security and Compliance
Protecting sensitive data from unauthorized access throughout the pipeline is critical to complying with regulations such as GDPR, HIPAA, or others. However, ensuring data privacy and security can complicate pipeline development.
Solution
Implement end-to-end data encryption and access controls and conduct regular security audits. Staying informed about evolving regulatory requirements and implementing automated compliance checks within the pipeline can mitigate risks.
Data Pipeline Use Cases
Here are some of the most common and impactful use cases of a data pipeline:
Data Pipeline for AI Readiness Assessment
Through data cleaning, transformation, and integration, data pipelines can be a powerful tool to support AI readiness assessment and implementation. By automating data ingestion, processing, and preparation, a well-designed data pipeline can provide a comprehensive view of an organization’s data assets and help identify areas for improvement to support AI initiatives.
Batch Processing Pipelines
It is a common approach for handling large volumes of data at scheduled intervals. These pipelines are used for traditional analytics and business intelligence. They efficiently process historical data and repetitive tasks with minimal human intervention.
Data Migration and Modernization
Data pipelines facilitate migration from legacy systems to modern data warehouses and lakes. They automate the extraction, transformation, and loading of data to enable analytics on consolidated datasets and support data-driven decision-making. Partnering with experts in data modernization services ensures this migration is efficient, secure, and aligned with enterprise growth goals.
In the next section, we’ll explore practical applications of real-time data pipelines and their ROI, showcasing how we’ve helped our clients successfully implement these solutions to drive tangible business value.
Real-World Applications of Data Pipelines & Their ROI
These case studies showcase Rishabh Software’s proficiency in planning and building data pipelines that enable real-time insights, unified data visibility, and tangible ROI across oil & gas, hospitality, and enterprise modernization initiatives.
Case Study 1: Interactive Well Data Platform for Oil & Gas
Client & Challenge
A major oil & gas exploration firm struggled to handle disparate well data (seismic readings, drilling logs, production metrics) coming in from multiple field locations. The lack of a unified pipeline caused delays in data-driven decision-making for drilling operations and resource optimization.

Data Pipeline Solution
- Cloud-Based Ingestion: Deployed a data pipeline on AWS to consolidate RRC and Comptroller data in near real time.
- Automated Data Quality: Set up cleansing, validation, and transformation processes to standardize well information.
- Integrated Dashboards: Provided advanced search, lease reporting, and geospatial mapping tools for instant analytics.
- Alerts & Monitoring: Enabled user-defined notifications to track changes in permits, purchases, and well pricing.
Outcomes & ROI
- 51% faster access to critical data
- 36% improvement in procurement decision accuracy
- 42% quicker response to market shifts, minimizing missed opportunities
Read more about how Oil and Gas Well Data Platform Development helped our client accelerate drilling decisions with real-time, unified well data.
Case Study 2: Unified Data Warehouse for Hospitality Giant
Client & Challenge
A North American hospitality pioneer (F&B, resorts, rental homes) grappled with fragmented data across 20+ applications (PMS, POS, analytics, inventory, and more). Acquisitions had led to siloed systems, redundant data, and limited visibility into performance metrics. The need for a single source of truth became critical to support real-time decision-making.
Data Pipeline Solution
- Cloud-Based Data Warehouse
Designed a centralized DWH on Microsoft Azure, consolidating data from disparate sources. - Operational Data Store (ODS)
Applied rules for data validity, de-duplication & sanity checks; built automated pipelines (Talend, SSIS) for continuous data ingestion. - ETL & Monitoring
Created ETL routines (SSIS) and microservices (ASP.NET Core) for seamless data flow & oversight; integrated APIs for Salesforce and other key apps. - Analytical Layer
Leveraged Microsoft SQL Server Analysis Services (SSAS) & Power BI to generate intuitive dashboards covering expense management, demand forecasting & customer satisfaction. - Deployment
Implemented on Microsoft Azure after a detailed comparative analysis, ensuring scalability and cost-efficiency.
Outcomes & ROI
- 50% increase in workflow efficiency by centralizing and standardizing data
- 40% reduction in data quality issues through automated validation processes
- 99% accuracy in on-the-go business insights, enabling faster strategic decisions
Learn more about how a Data Warehouse Solution for Hospitality Business improved operational efficiency and data accuracy across 20+ systems.
Case Study 3: Scalable Platform for Beer-Line Cleaning Provider
Client & Challenge
A Europe-based provider of automated beer-line and water-dispenser cleaning systems managed two separate, overlapping codebases. Fragmented data structures led to high maintenance costs, limited real-time analytics, and bottlenecks in scaling to meet rising customer demands.
Data Pipeline Development
- Microservices Unification: Consolidated both systems into a multi-tenant microservices architecture (Angular 18, .NET 8, PostgreSQL), creating a single ingestion framework for diverse data streams.
- Standardized APIs & ETL: Built uniform APIs and ETL jobs to merge and transform data from legacy platforms, ensuring seamless data flow and reducing redundancy.
- Cloud-Ready Scalability: Implemented a database-per-tenant model for strict data isolation, enabling efficient scaling as new clients join.
- Advanced Notifications: Integrated real-time alerts and escalation services, triggering automated maintenance workflows based on predefined business rules.
Outcomes & ROI
- 60% reduction in maintenance overhead by merging duplicated functionalities.
- 300% boost in system capacity, accommodating a larger tenant base without performance lags.
- 100% isolation of customer data with multitenancy
Discover how Multiple System Codebases Reengineering enabled scalable, cost-effective operations through unified architecture.
Hybrid Data Pipeline Architectures & ML Integration: A Rishabh Software Perspective
Modern businesses often find themselves caught between legacy on-premises systems which are critical for regulatory reasons and the scalability of cloud services. Whether it’s a global manufacturing giant with decades-old mainframes or a FinTech institution struggling to stay compliant, the pressure to innovate without disrupting core operations is overwhelming.
At Rishabh Software, we’ve assisted clients facing these exact dilemmas. We enable a seamless flow of information from on-premises databases to cloud-based analytics platforms by architecting hybrid data pipelines. Our approach delivers real-time data availability, data integrity, and compliance across both environments. We help you lay the technical groundwork not just for BI, but for AI and ML initiatives as well.
Here’s How We Do It:
- We conduct in-depth assessments of existing infrastructures, identifying what data remains on-prem and what can effectively move to the cloud.
- Our experts combine on-prem ingestion tools with AWS or Azure to unify your data ecosystem.
- We embed role-based access control, encryption, and auditing across the pipeline to ensure stringent data governance.
- We ensure your data is clean, consistent, and audit-ready which are critical prerequisites for AI-readiness.
The Outcome: Flexible, cost-effective data operations that offer the best of both worlds – on-premise stability with cloud-driven innovation. You can count on us to create a foundation for advanced analytics and AI-driven decisioning.
Tapping Into Advanced Insights with ML Integration
As organizations accumulate more data, they’re eager to move beyond mere reporting to predictive analytics and AI-driven insights. From personalized product recommendations to detecting fraudulent transactions in real time, ML is the natural next step.
Nevertheless, many enterprises discover that ML integration isn’t just about choosing the right model. It’s about preparing data for training at scale, continuously deploying new models, and monitoring them to ensure performance doesn’t degrade over time.
At Rishabh Software, we build data pipeline solutions with AI-readiness at their core. We ensure that real-time, enriched, and trusted data flows seamlessly into ML workflows built on frameworks like TensorFlow, PyTorch, and Scikit-learn.
Rishabh Software serves as a holistic partner in this journey. Data pipeline solutions do more than just ingest and transform data; they feed clean, relevant information directly into ML frameworks like TensorFlow, PyTorch, or Scikit-learn. Our data engineers team up with data science teams to ensure that high-quality, up-to-date data is always available for model training.
Key Pillars of ML-Ready Pipelines:
- Data Preparation for Automated feature extraction, data enrichment, and real-time anomaly detection.
- Model Deployment and integration with Kubeflow or MLflow to facilitate continuous model delivery and one-click deployments to production environments.
- Ongoing Performance Monitoring: Real-time dashboards and alerts to track drift in model accuracy, ensuring you can retrain or roll back models as needed.
The Outcome: End-to-end AI systems that scale from proof-of-concept to production and deliver consistent, data-driven ROI through smarter, faster decisions.
Transform Your Data Journey with Rishabh Software’s Proven Data Engineering Expertise
As a leading data engineering company, we empower global enterprises to solve complex data challenges. Our deep domain expertise and innovative solutions ensure that your data pipeline is operational and optimized for maximum effectiveness.
Our expert data engineers provide end-to-end data lifecycle management, covering everything from planning and strategizing to implementation. This holistic approach ensures that your data pipeline is built efficiently and aligned with your business objectives, allowing seamless integration and optimized performance.
Leverage our services to build a resilient data infrastructure that drives growth and innovation. By integrating artificial intelligence and data engineering capabilities, our expert team stands ready to amplify your organization’s data roadmap.
We offer comprehensive ETL services, crucial for consolidating data from multiple sources into a single repository. Our data warehouse consulting and development services are designed to create a single version of the truth, empowering stakeholders to derive valuable insights and make informed decisions.
Frequently Asked Questions
Q: How do we ensure data quality in a data pipeline?
A: Here are some relevant strategies that help in ensuring data quality.
- Data Validation: Implement checks to verify data accuracy and completeness during ingestion.
- Automated Testing: Automated tests help you identify and rectify data issues before processing.
- Monitoring: Continuously monitor data flows and quality metrics to detect anomalies.
- Data Profiling: Regularly analyze data to understand its structure, content, and quality.
- Error Handling: Establish robust error-handling mechanisms to address issues promptly.
Q: What are the key components of a data pipeline and how do they work?
A: A complete data pipeline has several key parts that work together to move and transform your data.
- Data sources are where your raw data comes from. These might include databases, files, APIs, or applications.
- Data ingestion brings data into the pipeline using either batch processing or real-time streaming depending on how quickly you need to access the data.
- Data processing cleans formats, combines and transforms your raw data into actionable insights for your business
- Data storage serves as a repository for both raw and processed data. The choice at this stage, among databases, data lake or data warehouse, depends on factors like data structure, volume, access patterns, and analytical needs
- Data analysis uses tools like SQL, business intelligence dashboards or machine learning algorithms to find patterns and insights in your data
- Data visualization turns complex data into easy-to-understand charts and reports so your team can make better decisions
- Monitoring and orchestration make sure everything runs smoothly by tracking pipeline performance, scheduling tasks and handling errors automatically.
Q: Why does data ingestion matter?
A: Data ingestion matters because:
- This is the first step in your pipeline, and it sets the pace for everything that follows
- Batch ingestion is a good choice when you need data at regular intervals like every hour or once a day
- Streaming ingestion is best when you need data right away such as tracking user activity in real time
- Choosing the right ingestion method helps you stay efficient and make faster decisions
Q: How do I decide where to store my data?
A: The best storage option depends on your needs:
- Use a database if you need quick access to structured data
- Use a data warehouse when you need to run reports and queries on clean structured data
- Use a data lake when you need to store large amounts of raw or unstructured data
Q: What is the difference between ETL and ELT pipelines?
A: ETL pipelines extract data from sources, clean and transform it, then load it into a system like a data warehouse. This approach works well when your data needs to be processed before it is stored.
ELT pipelines extract data, then load it directly into storage without processing it first. The transformation happens later. This approach is useful for large raw data sets and works well with cloud storage systems.
Both approaches help move data effectively. You can choose one based on your volume of data and how flexible your processing needs are. To learn more about these two major data pipeline architectures, read our blog post on ETL vs ELT, where we explore key differences to help you decide when to choose one over the other.
Also, read our blog post on the importance of the ETL data pipeline process, where we explore common ETL use cases and key tools that can help enhance your organization’s data management and decision-making capabilities.
Q: Why should I care about monitoring and orchestration?
A: Monitoring and orchestration keep your data pipeline running without problems. Monitoring tools identify delays or errors and alert if something goes wrong. Orchestration tools schedule and manage each task in your pipeline to ensure everything happens in the right order. Together, they help you avoid data loss, reduce downtime, and keep your analytics accurate and up to date.
Q: What is a data pipeline?
A: Data Pipeline refers to a method that automates data movement and transformation from various sources to a destination, commonly a data warehouse or database. It enables efficient data collection, processing, and analysis, which helps organizations in refining the right data for decision-making.
Q: How many types of data pipelines are there?
A: There are several types of data pipelines, but here are the three main types:
- Batch Data Pipelines: These pipelines process data in large blocks at scheduled intervals. They are suitable for scenarios where real-time data processing is not critical.
- Streaming Data Pipelines: It is ideal for applications requiring low latency and immediate decision-making capabilities, such as fraud detection or real-time monitoring.
- Hybrid Data Pipelines: These pipelines combine elements of both batch and real-time processing. They handle some data in batches while processing other data streams in real-time. This approach offers flexibility in handling different data types and use cases.
Q: Do I really need a data pipeline?
A: If your data flows in from ten different systems, each with its own format, schema quirks, and update schedules then yes, a data pipeline isn’t just helpful, it’s critical infrastructure. It’s your translator, orchestrator, and logistics manager all rolled into one. Without a pipeline, you’re manually cleaning, transforming, and stitching data together. This is a painful, error-prone process that’s never scalable. But with a well-designed pipeline? You get streamlined ingestion, automated transformations, consistent data models, and near real-time availability. It turns chaotic data streams into reliable, actionable intelligence. If you care about data quality, operational efficiency, and making timely, informed decisions then yeah, you definitely need a data pipeline.







