
AI adoption is accelerating faster than data infrastructure can keep up. Most of the organizations have spent years collecting and storing data, but very few have built the kind of foundation that modern AI workloads actually demand. Here, the gap is not about volume. As many organizations are running data lake initiatives, built on agile and iterative approaches, that make sense for reporting and analytics.
As AI initiatives mature, the rules change. AI workloads require more than a place to land data; it requires structure, continuity, and a pipeline that keeps data clean, governed, and model-ready at every stage. However, traditional data lake was never developed with AI in mind, and that gap becomes impossible to ignore the moment AI workloads enter the picture.
This blog focuses on bridging that gap. It covers what changes when you build a data lake specifically for AI, core principles behind it, real-world use cases, and decisions that move organizations from data collection to AI readiness.
How a Data Lake Built for AI Differs from a Traditional One
A traditional data lake and an AI-ready data lake may look similar on the surface but serve entirely different purposes. The table below breaks down where those differences matter.
| Aspect | Traditional Data Lake | Data Lake for AI | Comment/justification |
| Primary Role | Stores and organizes data | Supports data consumption across AI workflows | Good; “AI workflows” is a bit broader than just “analytics.” |
| Data Flow | Primarily batch processing | Batch + real‑time data pipelines | Accurate: AI increasingly blends batch and streaming. |
| Data Readiness | Raw, schema‑on‑read | Refined, validated, and model‑ready | Trad‑lake: “raw, schema‑on‑read” is standard description. AI‑lake: “refined, validated, model‑ready” correctly captures curation, feature‑ready datasets. |
| Usage Pattern | Analytics and reporting | Analytics, ML training, and inference | Correct; AI‑lake explicitly supports training and inference workloads. |
| Processing | Periodic transformation | Continuous data refinement | “Periodic” is fine for trad; “continuous refinement” (features, quality, lineage) is accurate for AI‑contexts. |
| System Design | Centralized storage layer | Integrated data layer across systems | Traditional: “centralized storage” is broadly accurate. AI‑lake: “integrated data layer across systems” is reasonable, provided you mean it spans storage, catalog, compute, and AI tooling. |
| Data Types | Structured and unstructured | Structured, unstructured, and evolving formats (e.g., vector data) | Correct; AI‑lake explicitly includes embeddings/vector data for RAG, LLMs, vision, etc. |
| Outcome Focus | Managing data at scale | Enabling reliable AI‑driven outcomes | “Managing data at scale” fits classic data‑lake focus. “Reliable AI‑driven outcomes” correctly shifts from storage to AI‑quality and governance. |
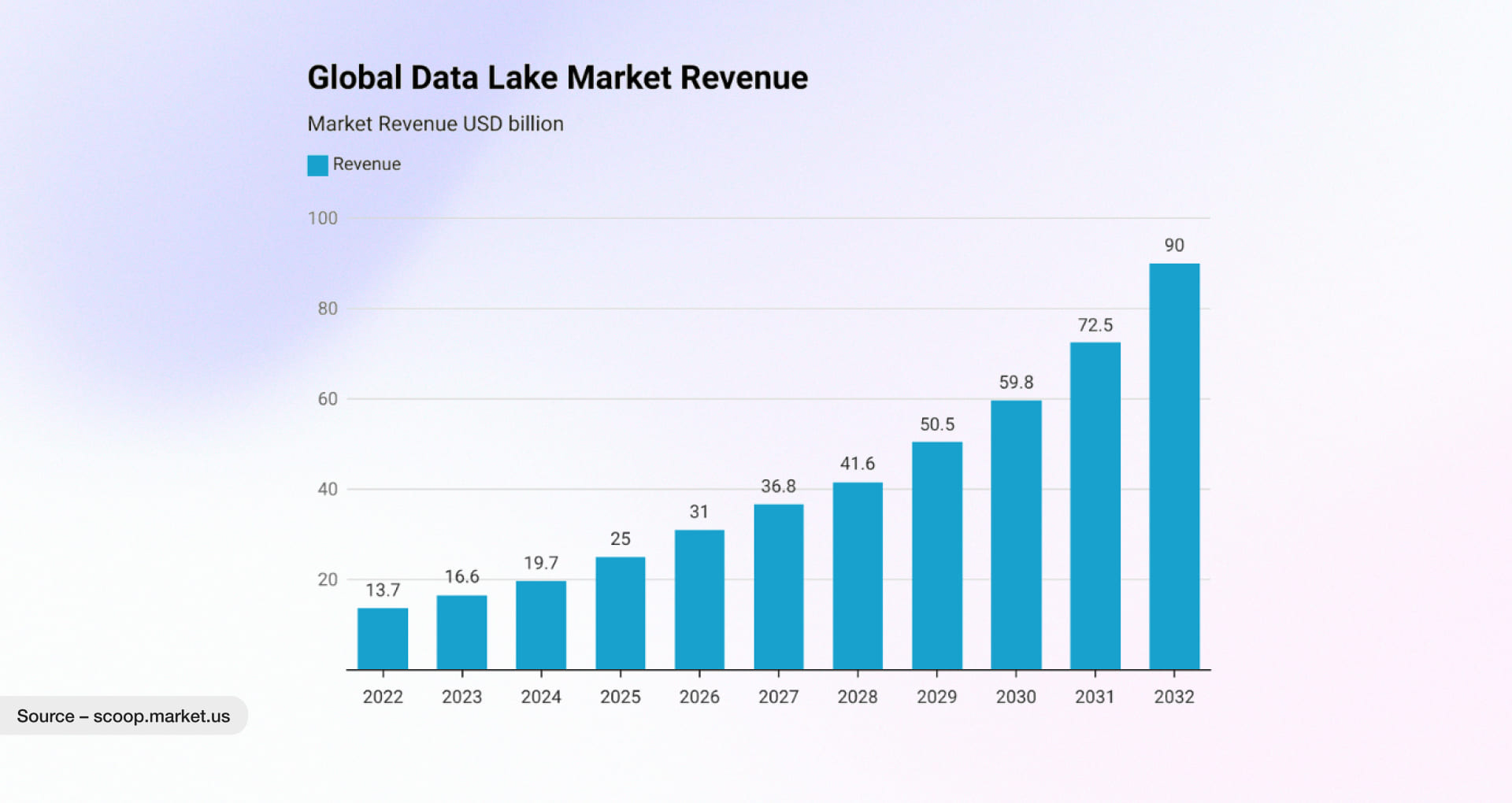
Core Principles Before You Start Building a Modern Data Lake for AI
AI and ML systems have become more effective over time, but only when the data they rely on remains relevant, accurate, and consistent. If the data loses quality or context, the outcomes lose value. This is where a data lake for AI moves beyond traditional enterprise data management and becomes part of how the system actually works.
These principles define how data moves from being stored to being used, and how AI systems remain effective as conditions change.
Design for Data Consumption, Not Storage
Most data lakes begin with the goal of capturing and holding data at scale. It works well for centralization. But AI does not operate on stored data alone. It depends on data that is already prepared and ready to move across training and inference workflows. The design, therefore, needs to start with how data will be consumed, not just where it will live.
Plan for Batch and Real-Time Together
Batch processing has been the default for a long time, and it continues to support large-scale data transformation. But AI systems rely on a mix of historical and real-time data to stay relevant. When these are designed separately, gaps start to appear in consistency and performance. Bringing both together early avoids that disconnect.
Build for Data Reliability and Lineage
As data grows, flexibility increases, but so does uncertainty. Without clear lineage and validation, it becomes difficult to trace issues or trust outputs. AI systems amplify this problem because they depend on consistent inputs. Reliability, in this case, is not an added layer. It is part of the foundation and is largely defined during the data lake strategy stage.
Support Structured, Unstructured, and Evolving Data Types
Data lakes have always handled structured and unstructured data. That part remains unchanged. What is changing is the introduction of newer formats like vector data, driven by modern AI use cases. Designing for this early avoids the need to rebuild systems as requirements evolve.
Real-World AI Use Cases Powered by the Data Lake
A modern data lake for AI shapes how real-world use cases are built and delivered. Built on a modern data lake architecture and evolving toward a data lake house architecture, it supports secure data handling and automated onboarding through extraction, normalization, and deduplication. This is what allows AI use cases to move from isolated experiments to systems that operate continuously and at scale.
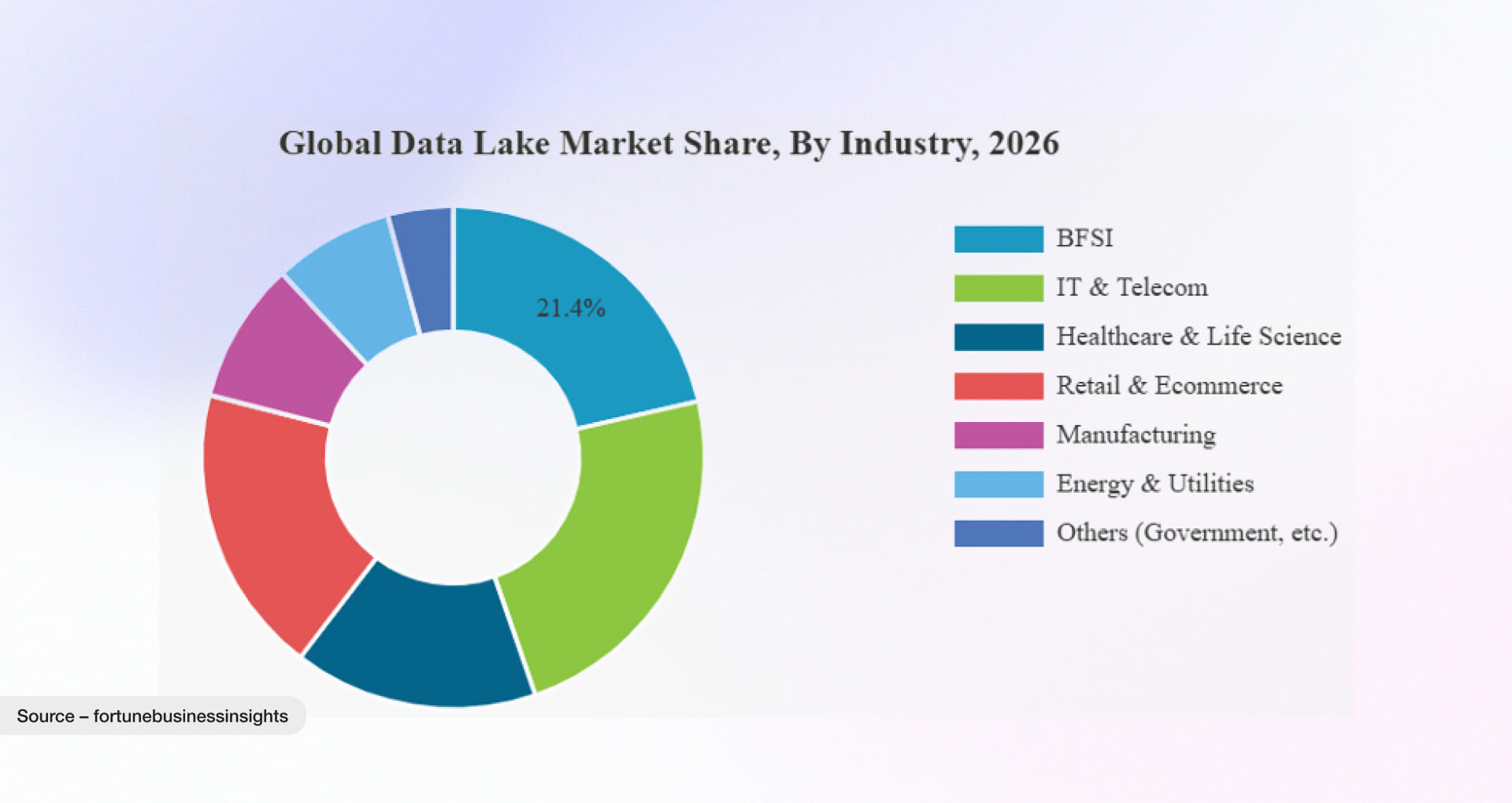
The pie chart below shows how the data lake market is expected to expand across various industry verticals, including BFSI, retail, and digital manufacturing, as organizations enter the market and take advantage of emerging opportunities.
Fraud Detection in High-Volume Transaction Systems
(Where: Banking, fintech | When: Real-time transactions)
Fraud is not a slow problem. It appears in the middle of a transaction and disappears just as quickly. And with the time it growing drastically, with scams causing $64B in losses and affecting 70% of Americans, according to the 2025 State of Scams USA report.
Models depend on signals coming from multiple places at once—transaction logs, user behavior, and live streams of activity. A modern data lake for AI brings these inputs together as they arrive, aligns them, and keeps them usable. The result is not just faster processing, but decisions made while the event is still unfolding.
Flow:
Transactions → Data Lake → Real-Time Processing → AI Model → Risk Score
Personalization at Scale in Digital Platforms
(Where: E-commerce, OTT, SaaS | When: Every user interaction)
User behavior rarely repeats itself in the same way twice. It shifts with context, timing, and intent.
A modern data lake architecture for AI holds these signals together, even when they originate from different systems. With consistent data flowing in, models adjust recommendations continuously, not in intervals. Personalization becomes less about prediction and more about staying in step with the user.
Predictive Maintenance in Industrial Systems
(Where: Manufacturing, IoT | When: Continuous sensor data)
Machines do not fail without signals. The signals are simply easy to miss when data is scattered or delayed.
A modern data lake for AI captures sensor data as it is generated and keeps it in a form that models can use. Patterns emerge over time, and with them, early indications of failure. Maintenance shifts from reacting to breakdowns to recognizing them before they happen.
Enterprise Search and Generative AI Systems
(Where: Internal tools, knowledge systems | When: On-demand queries)
Most organizations already have the answers they need. The difficulty lies in finding them at the right moment.
A modern data Lakehouse architecture for AI brings documents, logs, and embeddings into a shared structure. This allows AI systems to retrieve context instead of isolated data points, making responses more grounded and less dependent on guesswork.
Demand Forecasting in Supply Chain Systems
(Where: Retail, logistics | When: Demand fluctuations)
Demand rarely follows a fixed pattern. It responds to factors that change faster than most systems can track.
A modern data lake for AI integrates these signals as they emerge sales, inventory, external inputs—and keeps them aligned. Models then work with a current view of the system, not a delayed one, making forecasts more responsive and decisions more relevant.
Key Metrics to Measure Your Data Lake’s Performance for AI-based System/Solution
Here is the uncomfortable truth about data lakes: most of them are clean and make sense in architecture diagrams and quietly broken in production. The S3 bucket exists. The Spark cluster hums. The dashboards load. And yet, when someone asks a real question, why did the model recommend that? Or when did this customer churn? The answer takes three days and requires a data engineer named Marcus.
Measuring a data lake’s performance for AI is not about throughput or storage costs. It is about whether the lake actually supports decisions at the speed decisions need to be made.
- Start with a real use case test. Not a synthetic benchmark. Pick a live AI output such as a fraud score, a recommendation, or a churn prediction and trace it backwards. Can you reconstruct every data input that produced it? If the answer depends on undocumented knowledge, the issue is not just data. It is a lack of structure.
- Check data availability across systems. The question is not whether data exists, but whether it is accessible when needed. Measure how much of the data used by AI models can be queried without engineering support. If access depends on multiple steps or dependencies, the system is not yet optimized for AI usage.
- Test freshness latency. How quickly does new data become usable? For fraud detection, even small delays matter. For reporting, they may not. The metric is not latency alone, but latency in relation to the decision it supports. Define acceptable thresholds for each use case.
- Review dependency on data teams. Look at how often model updates or new features require engineering intervention. If most changes depend on manual effort, the system is not yet enabling self-service. The goal is not to remove data teams, but to reduce unnecessary dependency.
- Validate decision speed end to end. Measure the time from event to action. Not just model inference, but the full flow including ingestion, processing, feature generation, and delivery. This reflects how the system performs in real conditions.
- Audit one AI output regularly. Select an output and trace it completely. If it cannot be explained clearly, the issue lies in data traceability. Systems that cannot be audited eventually lose trust.
Build AI-Ready Data Lake Foundations with Rishabh Software
Building a modern data lake for AI often looks straightforward at the start. The complexity shows up later, when data needs to move reliably across pipelines, support real-time use cases, and stay usable for evolving AI workloads. This is where the difference is not in tools, but in how the system is designed and connected from the beginning.
At Rishabh Software, the focus is on shaping that foundation through data engineering services that align architecture, pipelines, and governance with actual usage. Our teams work across data and AI systems to bring structure to fragmented environments, build modern data lake and data lake house architectures, and ensure data remains consistent across analytics and machine learning workflows. The outcome is a system that is not only scalable, but also usable where it matters.
Frequently Asked Questions
Q. What is an AI-ready data lake?
A. An AI-ready data lake is one where data is consistently shaped, validated, and prepared before it reaches a model. AI and ML models do not spend cycles interpreting or cleaning it, they simply consume it and perform.
Q. How does a data lake support real-time AI?
A. By removing the wait between data arriving and data being used. In practice, events from systems including transactions, logs, and user actions are ingested as they happen. Instead of being stored and processed later, they move through streaming pipelines where they are cleaned, enriched, and made available immediately.
Q. What are the key components of modern data lake architecture?
A. A modern data lake is not defined by layers alone. It is defined by how data moves, stays reliable, and becomes usable across systems.
- Ingestion: where data enters, from systems, events, and streams
- Storage: where data lives, in its raw and evolving forms
- Processing: where data is shaped, cleaned, and made usable
- Metadata & Catalog: where data gains meaning and context
- Governance: where control, access, and trust are established
- Access Layer: where data is read, queried, and shared without duplication
- AI/ML Integration: where data connects to models and decision-making
- Orchestration & Monitoring: where the system is kept running, observed, and corrected
Q. How do you ensure data quality in a data lake for AI?
A. Data quality checking process go hand and hand from initial stage to final. You build it into the path data takes. Here are some crucial ways you can ensure data quality in data lake for AI:
At ingestion (data entry point):
- Validate schema and data types
- Reject incomplete or corrupted records
- Tag data with metadata for traceability
During processing (pipeline stage):
- Normalize formats across sources
- Deduplicate records
- Apply transformation rules consistently
- Handle nulls and outliers early
At development level (engineering workflow):
- Version-control pipelines (Git-based)
- Test transformations with sample datasets
- Validate edge cases before deployment
During testing (QA and validation):
- Compare expected vs actual outputs
- Run data profiling checks (distribution, anomalies)
- Validate feature consistency for ML models
In production (monitoring and control):
- Track data freshness and latency
- Monitor volume spikes or drops
- Set alerts for pipeline failures
- Use lineage to trace issues back to source
Final check (before AI usage):
- Ensure data is consistent across training and inference
- Validate feature readiness
- Confirm no drift in data patterns







